一、前提条件
- 安装了Fiddler了(用于抓包分析)
- 谷歌或火狐浏览器
- 如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器
- 有Python的编译环境,一般选择Python3.0及以上
声明:本次爬取腾讯视频里 《最美公里》纪录片的评论。本次爬取使用的浏览器是谷歌浏览器
二、分析思路
1、分析评论页面

根据上图,我们可以知道:评论使用了Ajax异步刷新技术。这样就不能使用以前分析当前页面找出规律的手段了。因为展示的页面只有部分评论,还有大量的评论没有被刷新出来。
这时,我们应该想到使用抓包来分析评论页面刷新的规律。以后大部分爬虫,都会先使用抓包技术,分析出规律!
2、使用Fiddler进行抓包分析——得出评论网址规律
fiddler如何抓包,这个知识点,需要读者自行去学习,不在本博客讨论范围。

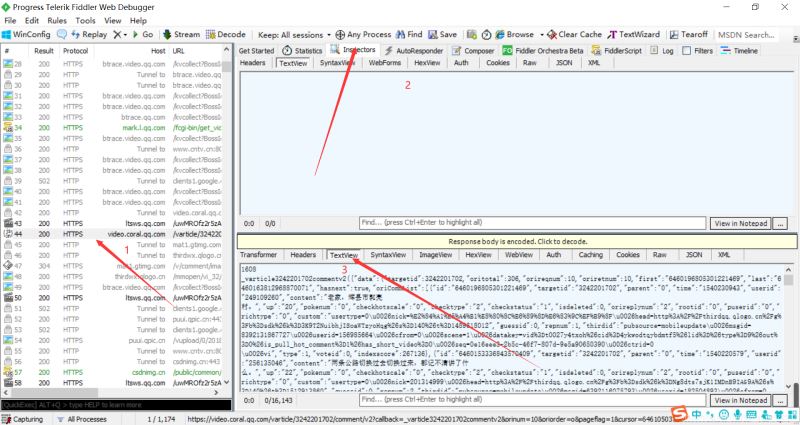
把上面两张图里面的内容对比一下,可以知道这个JS就是评论存放页面。(这需要大家一个一个找,一般Ajax都是在JS里面,所以这也找JS进行对比即可)
我们复制这个JS的url:右击 > copy > Just Url
大家可以重复操作几次,多找几个JS的url,从url得出规律。下图是我刷新了4次得到的JS的url:

根据上图,我们发现url不同的地方有两处:一是cursor=?;二是_=?。
我们很快就能发现 _=?的规律,它是从1576567187273加1。而cursor=?的规律看不出来。这个时候找到它的规律呢?
(1)百度一下,看前人有没有爬取过类型的网站,根据他们的规律和方法,去找出规律;
(2)羊毛出在羊身上。我们需要有的大胆想法——会不会这个cursor="htmlcode">
url = https://video.coral.qq.com/varticle/3242201702/comment/v2"text-align: center">
如下:
一般情况下,我们还要多试几次,确定我们的想法是正确的。
至此,我们发现了评论的url之间的规律:
- _=?从1576567187273加1
- cursor=?的值存在上面一个JS中。
三、代码编写
import re
import random
import urllib.request
#构建用户代理
uapools=["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0",
]
#从用户代理池随机选取一个用户代理
def ua(uapools):
thisua=random.choice(uapools)
#print(thisua)
headers=("User-Agent",thisua)
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#设置为全局变量
urllib.request.install_opener(opener)
#获取源码
def get_content(page,lastId):
url="https://video.coral.qq.com/varticle/3242201702/comment/v2"+lastId+"&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_="+str(page)
html=urllib.request.urlopen(url).read().decode("utf-8","ignore")
return html
#从源码中获取评论的数据
def get_comment(html):
pat='"content":"(.*"'
rst = re.compile(pat,re.S).findall(html)
return rst
#从源码中获取下一轮刷新页的ID
def get_lastId(html):
pat='"last":"(.*"'
lastId = re.compile(pat,re.S).findall(html)[0]
return lastId
def main():
ua(uapools)
#初始页面
page=1576567187274
#初始待刷新页面ID
lastId="6460393679757345760"
for i in range(1,6):
html = get_content(page,lastId)
#获取评论数据
commentlist=get_comment(html)
print("------第"+str(i)+"轮页面评论------")
for j in range(1,len(commentlist)):
print("第"+str(j)+"条评论:" +str(commentlist[j]))
#获取下一轮刷新页ID
lastId=get_lastId(html)
page += 1
main()
四、结果展示

总结
以上所述是小编给大家介绍的Python爬取腾讯视频评论,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件! 如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
稳了!魔兽国服回归的3条重磅消息!官宣时间再确认!
昨天有一位朋友在大神群里分享,自己亚服账号被封号之后居然弹出了国服的封号信息对话框。
这里面让他访问的是一个国服的战网网址,com.cn和后面的zh都非常明白地表明这就是国服战网。
而他在复制这个网址并且进行登录之后,确实是网易的网址,也就是我们熟悉的停服之后国服发布的暴雪游戏产品运营到期开放退款的说明。这是一件比较奇怪的事情,因为以前都没有出现这样的情况,现在突然提示跳转到国服战网的网址,是不是说明了简体中文客户端已经开始进行更新了呢?